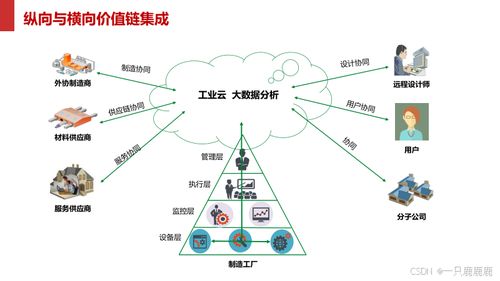
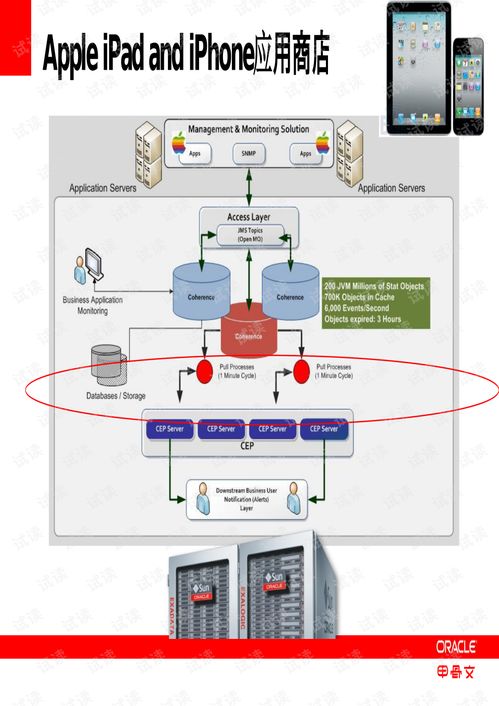
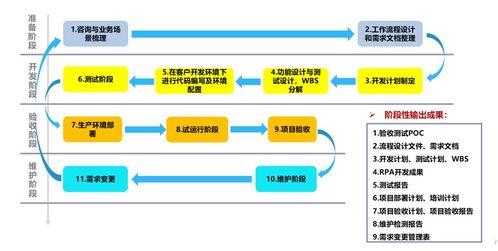
在當今數據驅動的時代,企業日益依賴大數據來驅動決策、優化運營和創新服務。隨著數據量的爆炸式增長和數據來源的多樣化,傳統集中式、IT主導的數據治理模式已難以滿足業務部門對數據訪問、分析和應用的敏捷性需求。在此背景下,以用戶為中心的自服務大數據治理應運而生,特別是其核心組成部分——數據處理服務,正成為賦能業務用戶、釋放數據價值的關鍵。
一、自服務大數據治理的核心:以用戶為中心
傳統數據治理往往由IT部門主導,流程繁瑣、響應周期長,業務用戶(如數據分析師、業務經理等)在數據獲取、處理和使用的各個環節都嚴重依賴技術團隊。這種模式不僅效率低下,更成為數據價值轉化的瓶頸。
以用戶為中心的自服務大數據治理顛覆了這一范式。其核心理念是將數據能力“民主化”,讓最懂業務需求的終端用戶能夠在受控、安全的環境中,自主完成數據的查找、理解、加工和分析。數據處理服務正是實現這一理念的技術基石和關鍵入口。它不再是IT部門的專屬工具,而是轉變為一種面向業務用戶的、易用且強大的自助服務。
二、數據處理服務:自服務能力的關鍵支柱
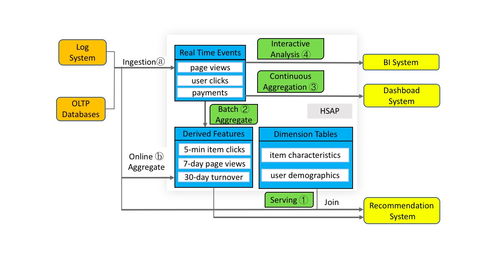
在自服務治理架構中,數據處理服務通常指一套集成的平臺或工具集,允許業務用戶通過圖形化界面、自然語言或簡單腳本,自助完成一系列數據操作,而無需深度的編程知識或直接操作底層復雜系統。其主要功能包括:
- 數據發現與目錄:提供企業級數據目錄,用戶能像在圖書館檢索一樣,輕松找到所需的數據資產,并理解其業務含義、來源、質量情況和血緣關系。
- 數據準備與清洗:通過拖拽式操作或簡單公式,用戶可以完成數據抽取、格式轉換、缺失值處理、異常值剔除、數據合并等常見的清洗和準備工作,將原始數據轉化為適合分析的“干凈”數據。
- 數據轉換與加工:支持用戶定義計算字段、數據聚合、數據透視等操作,以構建滿足特定分析需求的數據集或特征。
- 自助式數據查詢與分析:集成或提供與商業智能(BI)工具、分析環境的無縫對接,用戶可以直接對處理好的數據運行查詢、創建可視化報表和進行探索性分析。
- 協作與共享:用戶可以將自己處理好的數據流程(如清洗規則、轉換邏輯)封裝為可復用的“數據服務”或“數據產品”,在團隊或組織內安全地共享,促進知識沉淀和協作效率。
三、實現以用戶為中心的數據處理服務的挑戰與策略
盡管前景廣闊,但構建成功的自服務數據處理體系也面臨諸多挑戰:
- 平衡賦能與控制:如何在賦予用戶自主權的確保數據安全、合規與質量?這需要建立完善的治理策略,如基于角色的訪問控制(RBAC)、數據血緣追蹤、操作審計、以及嵌入流程的數據質量校驗規則。
- 降低使用門檻:服務的核心是“易用性”。需要設計直觀的用戶體驗(UX),提供豐富的模板、預置函數和智能推薦(如自動推薦清洗方法),并輔以完善的培訓與社區支持。
- 保障性能與穩定性:當大量用戶同時進行自助處理時,底層計算和存儲資源可能面臨壓力。需要采用云原生架構、彈性伸縮的資源調度以及查詢優化技術來保障服務性能。
- 文化轉變與推廣:成功不僅依賴技術,更需要組織文化和思維的轉變。需要推動業務部門從“數據消費者”向“數據協作者”和“數據產品經理”的角色轉變,并建立相應的激勵和認可機制。
四、未來展望
以用戶為中心的自服務數據處理服務,是大數據治理演進的必然方向。隨著人工智能和機器學習技術的融入,未來的數據處理服務將更加智能化,例如自動識別數據質量問題、推薦最佳處理流程、甚至根據自然語言指令自動生成數據處理代碼。
它將使組織內的每一個成員都能成為“公民數據科學家”,讓數據真正流動起來,從成本中心轉化為驅動業務創新和增長的核心引擎。企業通過構建這樣的能力,不僅提升了運營效率,更在根本上塑造了面向未來的數據驅動型文化。